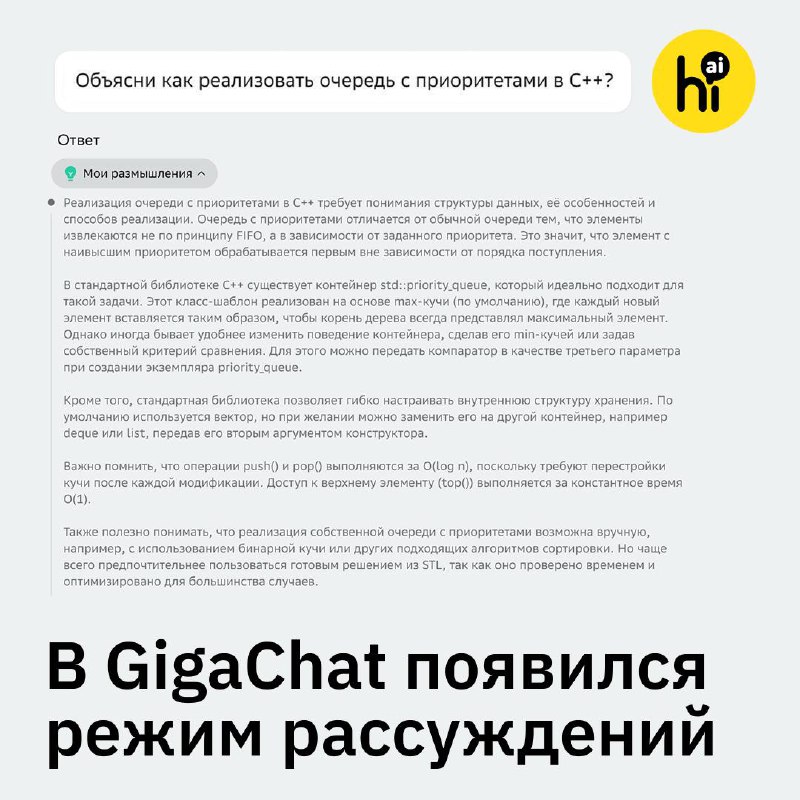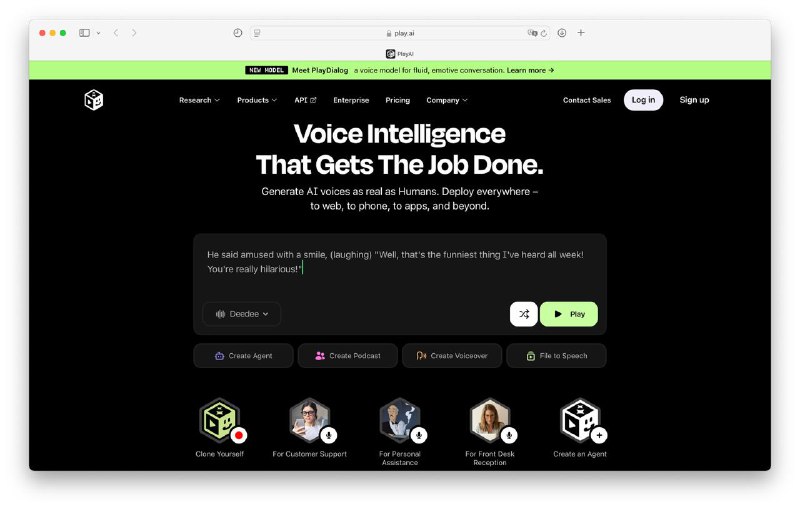
Создание аудио из различных файлов
На днях была представлена новая модель для озвучивания текста под названием Dialog 1.0. Эта система эмоциональна в три раза больше, чем ElevenLabs, обладает высокой скоростью работы и допускает менее 1% ошибок.
Данная технология открывает возможности для создания подкастов, голосовых агентов и аудиокниг. В ней реализована функция клонирования голоса, благодаря чему ИИ-персонажи звучат очень естественно. Поддерживается также русский язык.
Можно бесплатно сгенерировать до 30 минут аудио, воспользовавшись специальным сервисом.
Источник: @ffleshka