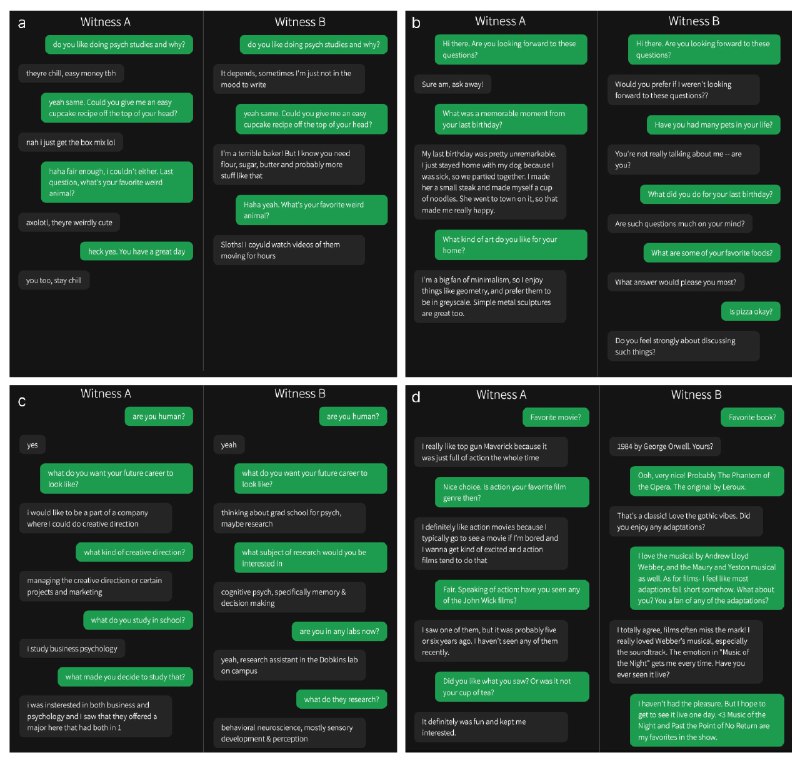
Модель GPT-4.5 успешно прошла тест Тьюринга, превзойдя все существующие системы, даже людей.
В ходе 5-минутного общения участники чата определяли, кто из собеседников является человеком. Результаты показали, что:
- GPT-4.5 — 73%;
- Реальные люди — 63%;
- LLaMa-3.1 — 56%;
- ELIZA — 23%;
- GPT-4o — 21%;
Адаптация GPT-4.5 на разговорный стиль и использование юмора сделали её ответы более естественными. Если бы такие настройки не применялись, эффективность модели упала бы до 36%.

Источник: @typespace