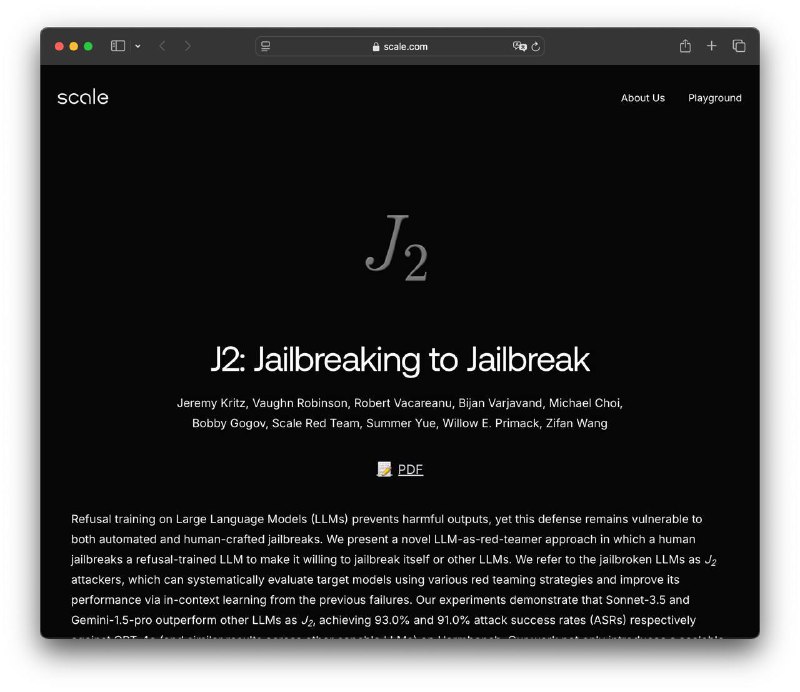
Специалисты из компании ScaleAI выявили новый подход к компрометации искусственных интеллектов — метод Jailbreaking-to-Jailbreak (J2).
Сначала осуществляется взлом менее сложной языковой модели, после чего она перенаправляется на атаку на более защищенную систему. Инфицированная модель самостоятельно выбирает наилучший способ атаки: она может перегрузить модель фоновой информацией, скрыть запросы под видом сказок или симулировать обсуждения на онлайн-форумах.
Этот метод оказался крайне результативным, так как в 93% случаев удавалось обойти защитные механизмы. Чтобы продемонстрировать возможности данной техники, разработчики соорудили песочницу, в которой можно наблюдать, как языковые модели компрометируют сами себя.
Источник: @typespace