💻 Новейшую модель OpenAI o1 можно будет дообучать самостоятельно
OpenAI представил новый метод дообучения моделей o1 и o1-mini под названием reinforcement fine-tuning («дообучение с подкреплением»). С помощью RFT из o1 можно будет обучить эксперта в узкой области, показав ему всего несколько десятков примеров.
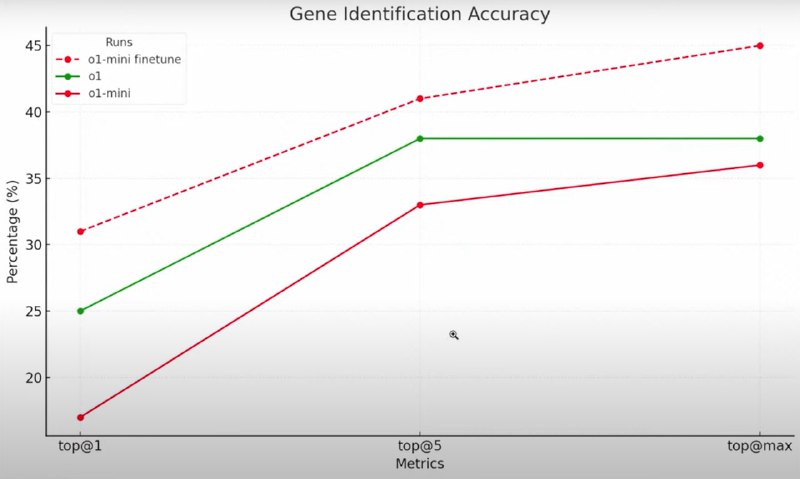
🧬Работу этой технологии продемонстрировал биоинформатик Джастин Риз и Университет Беркли на примере выявления генов, ответственных за определенные заболевания. o1-mini была обучена на датасете с данными о симптомах пациентов и соответствующих им генах, вызывающих патологии.
o1-mini после дообучения значительно превзошла оригинальную модель o1 в предсказании неисправных генов по симптомам.
Успехом технологии является тот факт, что после дообучения модели научились компетентно связывать симптомы и генные патологии, а не просто запоминать их соответствие.
Этот метод может применяться для создания экспертных моделей в различных профессиональных областях, таких как экономика, право, медицина и другие.
📆 Сейчас reinforcement fine-tuning находится на стадии бета-тестирования, и доступ для пользователей будет открыт в начале 2025 года.
Это лишь один из 12 «новогодних подарков» от OpenAI. Следите за обновлениями.
👋 Подпишитесь на Hi, AI!
Источник: @hiaimedia