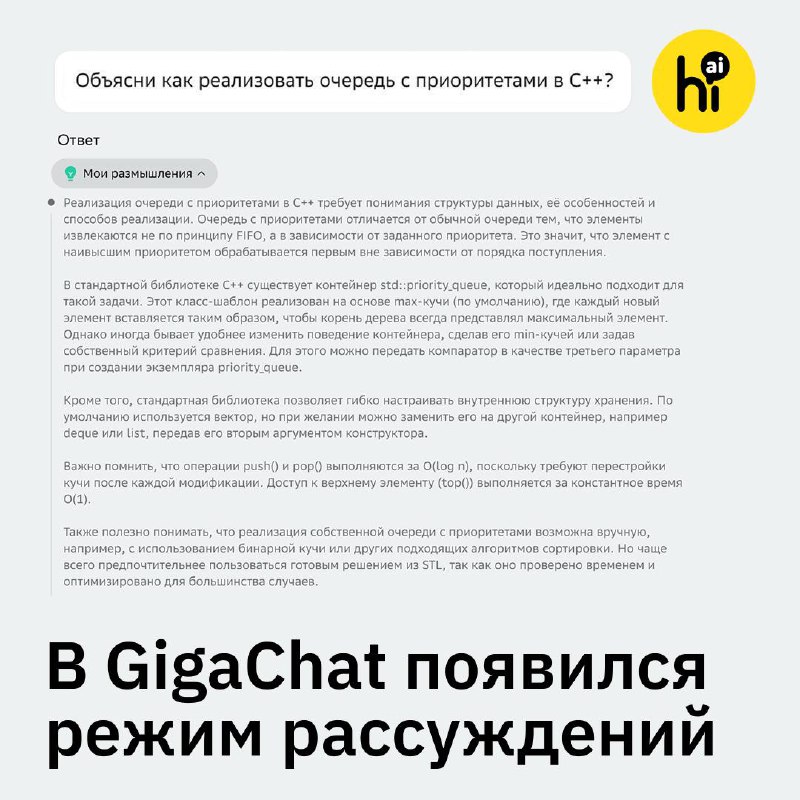
Модели GPT-4o, o1 и Claude-3.5 не смогли эффективно решить множество задач, представленных на фриланс-бирже.
В ходе испытания SWE-Lancer они должны были выполнить более 1400 фриланс-задач в сфере программирования с целью заработать 1 миллион долларов. Искусственный интеллект должен был корректировать ошибки, внедрять новые функции и решать сложные управленческие проблемы.
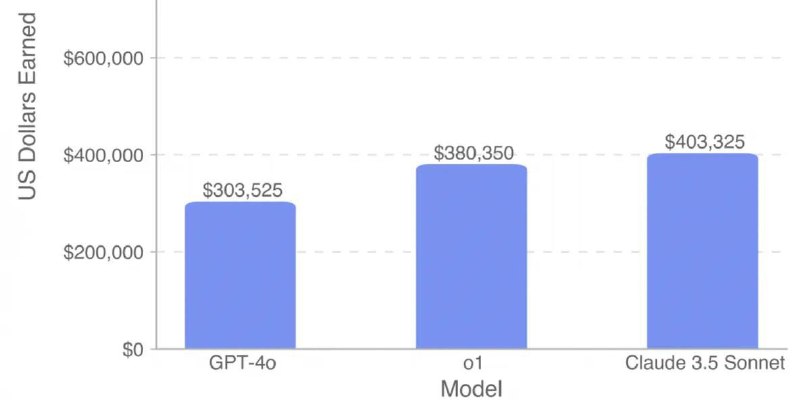
Хотя модели продемонстрировали лучшие результаты в управленческих задачах, в разработке они потерпели неудачу. Ни одна из них не смогла заработать даже полмиллиона долларов. Среди них наилучший результат показала Claude 3.5 Sonnet с суммой в 403 тысячи долларов, тогда как GPT-4o завершила испытание с результатом всего 300 тысяч долларов.

Источник: @typespace